Citizen Data Scientist, Module I: Introduction to Data Science: Laying the Foundation
Data Science is more than a buzzword—it’s a multidisciplinary field that blends statistics, algorithms, and domain knowledge to transform raw data into meaningful insights. In this first module, we explore the building blocks of Data Science, establishing a strong foundation for future learning.
Welcome to the first post in the Data Science series! So far, I’ve dived deep into Python and tackled the intricacies of Heat Transfer. Now, guided by the Citizen Data Scientist (CDS) Camp, co-developed by Silo AI and Scania Advanced Analytics, it’s time to get more into the proper Data Science. This course is designed to arm us with the skills to tackle real-world Data Science problems confidently.
This week, we kicked things off with an introduction to Data Science, exploring the fundamentals that set the stage for more complex topics to come. In this post, I’ll walk you through what I’ve learned, focusing on the key concepts, methodologies, and tools that are essential for any aspiring Data Scientist.

Common Terminology: Cutting Through the Buzz
In the world of Data Science, many terms are thrown around—AI, Machine Learning (ML), Deep Learning, Business Intelligence (BI), and more. But what do they really mean? Understanding how these concepts interconnect is crucial, as each plays a distinct role within the broader Data Science landscape.

The most common terminologies:
Data Science: The core discipline that leverages scientific methods, algorithms, and statistical models to extract knowledge from structured and unstructured data. It can be applied to predict future trends, as demonstrated in use cases like sales forecasting and image classification
Artificial Intelligence (AI): The overarching field that encompasses intelligent systems capable of performing tasks typically requiring human intelligence.
Machine Learning: A subset of AI, focused on creating systems that learn and improve over time as they are exposed to more data
Deep Learning: A specific subset of ML, involving neural networks with many layers, suited for handling vast amounts of unstructured data, such as images or text.
This interconnection between buzzwords highlights the different methods and approaches employed in Data Science, from predictive models to automated systems, with each component complementing the others
The Data Science Process: A Structured Approach
The CRISP-DM (Cross-Industry Standard Process for Data Mining) framework remains a central pillar in guiding Data Science projects. The iterative process of business understanding, data understanding, preparation, modeling, evaluation, and deployment underpins every successful project. Here’s a quick rundown:
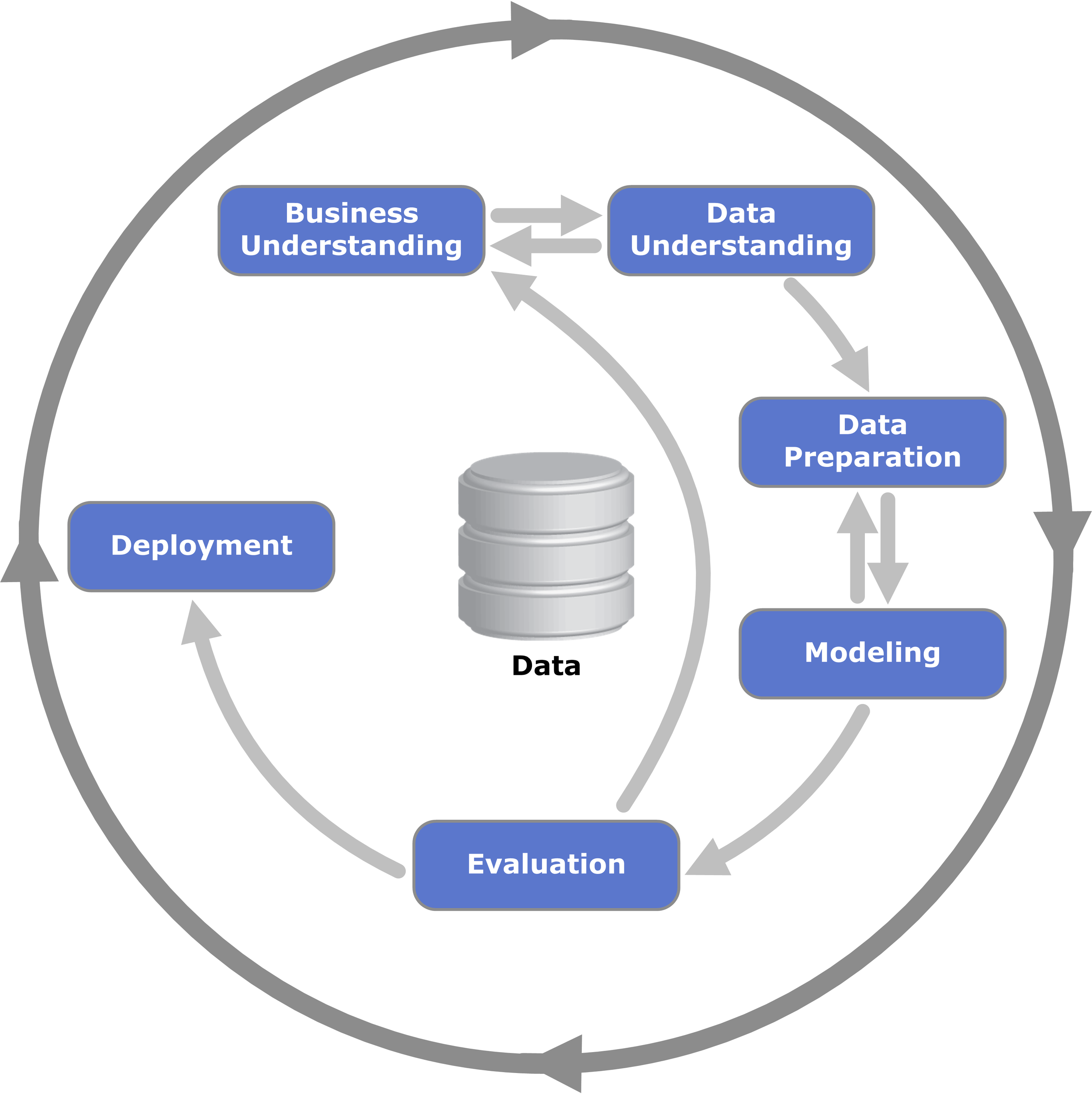
CRISP-DM:
Business Understanding: Defining the problem and understanding the business goals
Data Understanding: Identifying available data, its quality, and how it can address the business problem
Data Preparation: Cleaning, transforming, and structuring the data for modeling
Modeling: Selecting the appropriate models based on the problem and data characteristics
Evaluation: Assessing the model’s performance and making adjustments as needed
Deployment: Implementing the model into a real-world setting and monitoring its performance
The iterative nature of CRISP-DM emphasizes the importance of going back to earlier stages if needed. For example, during the data understanding phase, you may discover that the data lacks certain key features to answer the business question, requiring adjustments to the problem definition.
Practical Example: Mölnlycke Use Case
During the lecture, we also explored a practical example from the healthcare sector, which was fascinating but confidential, so I’ll keep the details abstract. In this real-world scenario involving Mölnlycke Health Care, the Data Science process was applied to develop a recommender system for wound treatment. The project began with a clear business goal: simplifying and improving wound care by recommending the best product for each patient. However, the data gathered revealed limitations, such as insufficient information about the products being used. This led to refining the business question to a more achievable goal—recommending the best product category based on wound characteristics.
The Mölnlycke case underscores the need for flexibility in Data Science projects. When the original business question couldn’t be fully addressed due to data limitations, the team redefined the objectives and focused on extracting the maximum value from the available data. Ultimately, the project achieved success by developing a model that performed better than random guessing, although regulatory hurdles delayed full deployment.
Machine Learning: The Heart of Data Science
At the core of Data Science lies Machine Learning. In this module, we learned how ML algorithms are trained to identify patterns and make predictions. There are several types of ML tasks, each serving a specific purpose:

ML Classification:
Supervised Learning: Models are trained on labeled data to predict outcomes. For instance, a model might classify whether a car is defective based on a set of images
Unsupervised Learning: Involves finding patterns in data without labeled outcomes. A common example is clustering customers into different groups based on behavior
Reinforcement Learning: Used in applications like game AI, where an agent learns by interacting with its environment and receiving feedback
A critical takeaway from this module was understanding that different problems require different approaches, and there’s no one-size-fits-all method in Data Science.
Conclusion: Foundations for Future Learning
This first module provided a solid introduction to key Data Science concepts, processes, and terminology. By breaking down the buzzwords, understanding the CRISP-DM process, and exploring real-world examples like Mölnlycke, we’re building the knowledge necessary to tackle more advanced topics in future modules. Stay tuned as we dive deeper into the technical aspects and applications of Data Science!